mirror of
https://github.com/danny-avila/LibreChat.git
synced 2025-12-19 09:50:15 +01:00
646 lines
23 KiB
Markdown
646 lines
23 KiB
Markdown
---
|
||
title: ✅ Compatible AI Endpoints
|
||
description: List of known, compatible AI Endpoints with example setups for the `librechat.yaml` AKA the LibreChat Custom Config file.
|
||
weight: -9
|
||
---
|
||
|
||
# Compatible AI Endpoints
|
||
|
||
## Intro
|
||
|
||
This page lists known, compatible AI Endpoints with example setups for the `librechat.yaml` file, also known as the [Custom Config](./custom_config.md#custom-endpoint-object-structure) file.
|
||
|
||
In all of the examples, arbitrary environment variable names are defined but you can use any name you wish, as well as changing the value to `user_provided` to allow users to submit their own API key from the web UI.
|
||
|
||
Some of the endpoints are marked as **Known,** which means they might have special handling and/or an icon already provided in the app for you.
|
||
|
||
## Anyscale
|
||
> Anyscale API key: [anyscale.com/credentials](https://app.endpoints.anyscale.com/credentials)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided, fetching list of models is recommended.
|
||
|
||
```yaml
|
||
- name: "Anyscale"
|
||
apiKey: "${ANYSCALE_API_KEY}"
|
||
baseURL: "https://api.endpoints.anyscale.com/v1"
|
||
models:
|
||
default: [
|
||
"meta-llama/Llama-2-7b-chat-hf",
|
||
]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "meta-llama/Llama-2-7b-chat-hf"
|
||
summarize: false
|
||
summaryModel: "meta-llama/Llama-2-7b-chat-hf"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "Anyscale"
|
||
```
|
||
|
||
|
||
|
||
## APIpie
|
||
|
||
> APIpie API key: [apipie.ai/dashboard/profile/api-keys](https://apipie.ai/dashboard/profile/api-keys)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided, fetching list of models is recommended as API token rates and pricing used for token credit balances when models are fetched.
|
||
|
||
- **Known issue:**
|
||
- Fetching list of models is not supported.
|
||
- Your success may vary with conversation titling
|
||
- Stream isn't currently supported (but is planned as of April 24, 2024)
|
||
- Certain models may be strict not allow certain fields in which case, you should use [`dropParams`.](./custom_config.md#dropparams)
|
||
|
||
??? tip "Fetch models"
|
||
This python script can fetch and order the llm models for you. The output will be saved in models.txt, formated in a way that should make it easier for you to include in the yaml config.
|
||
|
||
```py title="fetch.py"
|
||
import json
|
||
import requests
|
||
|
||
def fetch_and_order_models():
|
||
# API endpoint
|
||
url = "https://apipie.ai/models"
|
||
|
||
# headers as per request example
|
||
headers = {"Accept": "application/json"}
|
||
|
||
# request parameters
|
||
params = {"type": "llm"}
|
||
|
||
# make request
|
||
response = requests.get(url, headers=headers, params=params)
|
||
|
||
# parse JSON response
|
||
data = response.json()
|
||
|
||
# extract an ordered list of unique model IDs
|
||
model_ids = sorted(set([model["id"] for model in data]))
|
||
|
||
# write result to a text file
|
||
with open("models.txt", "w") as file:
|
||
json.dump(model_ids, file, indent=2)
|
||
|
||
# execute the function
|
||
if __name__ == "__main__":
|
||
fetch_and_order_models()
|
||
```
|
||
|
||
```yaml
|
||
# APIpie
|
||
- name: "APIpie"
|
||
apiKey: "${APIPIE_API_KEY}"
|
||
baseURL: "https://apipie.ai/v1/"
|
||
models:
|
||
default: [
|
||
"gpt-4",
|
||
"gpt-4-turbo",
|
||
"gpt-3.5-turbo",
|
||
"claude-3-opus",
|
||
"claude-3-sonnet",
|
||
"claude-3-haiku",
|
||
"llama-3-70b-instruct",
|
||
"llama-3-8b-instruct",
|
||
"gemini-pro-1.5",
|
||
"gemini-pro",
|
||
"mistral-large",
|
||
"mistral-medium",
|
||
"mistral-small",
|
||
"mistral-tiny",
|
||
"mixtral-8x22b",
|
||
]
|
||
fetch: false
|
||
titleConvo: true
|
||
titleModel: "claude-3-haiku"
|
||
summarize: false
|
||
summaryModel: "claude-3-haiku"
|
||
dropParams: ["stream"]
|
||
modelDisplayLabel: "APIpie"
|
||
```
|
||
|
||
|
||
|
||
## Apple MLX
|
||
> MLX API key: ignored - [MLX OpenAI Compatibility](https://github.com/ml-explore/mlx-examples/blob/main/llms/mlx_lm/SERVER.md)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
|
||
- API is mostly strict with unrecognized parameters.
|
||
- Support only one model at a time, otherwise you'll need to run a different endpoint with a different `baseURL`.
|
||
|
||
```yaml
|
||
- name: "MLX"
|
||
apiKey: "mlx"
|
||
baseURL: "http://localhost:8080/v1/"
|
||
models:
|
||
default: [
|
||
"Meta-Llama-3-8B-Instruct-4bit"
|
||
]
|
||
fetch: false # fetching list of models is not supported
|
||
titleConvo: true
|
||
titleModel: "current_model"
|
||
summarize: false
|
||
summaryModel: "current_model"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "Apple MLX"
|
||
addParams:
|
||
max_tokens: 2000
|
||
"stop": [
|
||
"<|eot_id|>"
|
||
]
|
||
```
|
||
|
||

|
||
|
||
## Cohere
|
||
> Cohere API key: [dashboard.cohere.com](https://dashboard.cohere.com/)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
- Experimental: does not follow OpenAI-spec, uses a new method for endpoint compatibility, shares some similarities and parameters.
|
||
- For a full list of Cohere-specific parameters, see the [Cohere API documentation](https://docs.cohere.com/reference/chat).
|
||
- Note: The following parameters are recognized between OpenAI and Cohere. Most are removed in the example config below to prefer Cohere's default settings:
|
||
- `stop`: mapped to `stopSequences`
|
||
- `top_p`: mapped to `p`, different min/max values
|
||
- `frequency_penalty`: mapped to `frequencyPenalty`, different min/max values
|
||
- `presence_penalty`: mapped to `presencePenalty`, different min/max values
|
||
- `model`: shared, included by default.
|
||
- `stream`: shared, included by default.
|
||
- `max_tokens`: shared, mapped to `maxTokens`, not included by default.
|
||
|
||
|
||
```yaml
|
||
- name: "cohere"
|
||
apiKey: "${COHERE_API_KEY}"
|
||
baseURL: "https://api.cohere.ai/v1"
|
||
models:
|
||
default: ["command-r","command-r-plus","command-light","command-light-nightly","command","command-nightly"]
|
||
fetch: false
|
||
modelDisplayLabel: "cohere"
|
||
titleModel: "command"
|
||
dropParams: ["stop", "user", "frequency_penalty", "presence_penalty", "temperature", "top_p"]
|
||
```
|
||
|
||
|
||
|
||
|
||
## Fireworks
|
||
> Fireworks API key: [fireworks.ai/api-keys](https://fireworks.ai/api-keys)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided, fetching list of models is recommended.
|
||
- - API may be strict for some models, and may not allow fields like `user`, in which case, you should use [`dropParams`.](./custom_config.md#dropparams)
|
||
|
||
```yaml
|
||
- name: "Fireworks"
|
||
apiKey: "${FIREWORKS_API_KEY}"
|
||
baseURL: "https://api.fireworks.ai/inference/v1"
|
||
models:
|
||
default: [
|
||
"accounts/fireworks/models/mixtral-8x7b-instruct",
|
||
]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "accounts/fireworks/models/llama-v2-7b-chat"
|
||
summarize: false
|
||
summaryModel: "accounts/fireworks/models/llama-v2-7b-chat"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "Fireworks"
|
||
dropParams: ["user"]
|
||
```
|
||
|
||
|
||
|
||
## Groq
|
||
> groq API key: [wow.groq.com](https://wow.groq.com/)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
|
||
- **Temperature:** If you set a temperature value of 0, it will be converted to 1e-8. If you run into any issues, please try setting the value to a float32 greater than 0 and less than or equal to 2.
|
||
|
||
- Groq is currently free but rate limited: 10 queries/minute, 100/hour.
|
||
|
||
```yaml
|
||
- name: "groq"
|
||
apiKey: "${GROQ_API_KEY}"
|
||
baseURL: "https://api.groq.com/openai/v1/"
|
||
models:
|
||
default: [
|
||
"llama3-70b-8192",
|
||
"llama3-8b-8192",
|
||
"mixtral-8x7b-32768",
|
||
"gemma-7b-it",
|
||
]
|
||
fetch: false
|
||
titleConvo: true
|
||
titleModel: "mixtral-8x7b-32768"
|
||
modelDisplayLabel: "groq"
|
||
```
|
||
|
||
|
||
|
||
## Huggingface
|
||
> groq API key: [wow.groq.com](https://wow.groq.com/)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
|
||
- The provided models are free but rate limited
|
||
|
||
- The use of [`dropParams`](./custom_config.md#dropparams) to drop "top_p" params is required.
|
||
- Fetching models isn't supported
|
||
- Note: Some models currently work better than others, answers are very short (at least when using the free tier).
|
||
|
||
- The example includes a model list, which was last updated on May 09, 2024, for your convenience.
|
||
|
||
```yaml
|
||
- name: 'HuggingFace'
|
||
apiKey: '${HUGGINGFACE_TOKEN}'
|
||
baseURL: 'https://api-inference.huggingface.co/v1'
|
||
models:
|
||
default: [
|
||
"codellama/CodeLlama-34b-Instruct-hf",
|
||
"google/gemma-1.1-2b-it",
|
||
"google/gemma-1.1-7b-it",
|
||
"HuggingFaceH4/starchat2-15b-v0.1",
|
||
"HuggingFaceH4/zephyr-7b-beta",
|
||
"meta-llama/Meta-Llama-3-8B-Instruct",
|
||
"microsoft/Phi-3-mini-4k-instruct",
|
||
"mistralai/Mistral-7B-Instruct-v0.1",
|
||
"mistralai/Mistral-7B-Instruct-v0.2",
|
||
"mistralai/Mixtral-8x7B-Instruct-v0.1",
|
||
"NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO",
|
||
]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO"
|
||
dropParams: ["top_p"]
|
||
modelDisplayLabel: "HuggingFace"
|
||
```
|
||
|
||
??? warning "Other Model Errors"
|
||
|
||
Here’s a list of the other models that were tested along with their corresponding errors
|
||
|
||
```yaml
|
||
models:
|
||
default: [
|
||
"CohereForAI/c4ai-command-r-plus", # Model requires a Pro subscription
|
||
"HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1", # Model requires a Pro subscription
|
||
"meta-llama/Llama-2-7b-hf", # Model requires a Pro subscription
|
||
"meta-llama/Meta-Llama-3-70B-Instruct", # Model requires a Pro subscription
|
||
"meta-llama/Llama-2-13b-chat-hf", # Model requires a Pro subscription
|
||
"meta-llama/Llama-2-13b-hf", # Model requires a Pro subscription
|
||
"meta-llama/Llama-2-70b-chat-hf", # Model requires a Pro subscription
|
||
"meta-llama/Llama-2-7b-chat-hf", # Model requires a Pro subscription
|
||
"------",
|
||
"bigcode/octocoder", # template not found
|
||
"bigcode/santacoder", # template not found
|
||
"bigcode/starcoder2-15b", # template not found
|
||
"bigcode/starcoder2-3b", # template not found
|
||
"codellama/CodeLlama-13b-hf", # template not found
|
||
"codellama/CodeLlama-7b-hf", # template not found
|
||
"google/gemma-2b", # template not found
|
||
"google/gemma-7b", # template not found
|
||
"HuggingFaceH4/starchat-beta", # template not found
|
||
"HuggingFaceM4/idefics-80b-instruct", # template not found
|
||
"HuggingFaceM4/idefics-9b-instruct", # template not found
|
||
"HuggingFaceM4/idefics2-8b", # template not found
|
||
"kashif/stack-llama-2", # template not found
|
||
"lvwerra/starcoderbase-gsm8k", # template not found
|
||
"tiiuae/falcon-7b", # template not found
|
||
"timdettmers/guanaco-33b-merged", # template not found
|
||
"------",
|
||
"bigscience/bloom", # 404 status code (no body)
|
||
"------",
|
||
"google/gemma-2b-it", # stream` is not supported for this model / unknown error
|
||
"------",
|
||
"google/gemma-7b-it", # AI Response error likely caused by Google censor/filter
|
||
"------",
|
||
"bigcode/starcoder", # Service Unavailable
|
||
"google/flan-t5-xxl", # Service Unavailable
|
||
"HuggingFaceH4/zephyr-7b-alpha", # Service Unavailable
|
||
"mistralai/Mistral-7B-v0.1", # Service Unavailable
|
||
"OpenAssistant/oasst-sft-1-pythia-12b", # Service Unavailable
|
||
"OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5", # Service Unavailable
|
||
]
|
||
```
|
||
|
||
|
||

|
||
|
||
|
||
## LiteLLM
|
||
> LiteLLM API key: master_key value [LiteLLM](./litellm.md)
|
||
|
||
**Notes:**
|
||
|
||
- Reference [LiteLLM](./litellm.md) for configuration.
|
||
|
||
```yaml
|
||
- name: "LiteLLM"
|
||
apiKey: "sk-from-config-file"
|
||
baseURL: "http://localhost:8000/v1"
|
||
# if using LiteLLM example in docker-compose.override.yml.example, use "http://litellm:8000/v1"
|
||
models:
|
||
default: ["gpt-3.5-turbo"]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "gpt-3.5-turbo"
|
||
summarize: false
|
||
summaryModel: "gpt-3.5-turbo"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "LiteLLM"
|
||
```
|
||
|
||
## Mistral AI
|
||
> Mistral API key: [console.mistral.ai](https://console.mistral.ai/)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided, special handling of message roles: system message is only allowed at the top of the messages payload.
|
||
|
||
- API is strict with unrecognized parameters and errors are not descriptive (usually "no body")
|
||
|
||
- The use of [`dropParams`](./custom_config.md#dropparams) to drop "user", "frequency_penalty", "presence_penalty" params is required.
|
||
- `stop` is no longer included as a default parameter, so there is no longer a need to include it in [`dropParams`](./custom_config.md#dropparams), unless you would like to completely prevent users from configuring this field.
|
||
|
||
- Allows fetching the models list, but be careful not to use embedding models for chat.
|
||
|
||
```yaml
|
||
- name: "Mistral"
|
||
apiKey: "${MISTRAL_API_KEY}"
|
||
baseURL: "https://api.mistral.ai/v1"
|
||
models:
|
||
default: ["mistral-tiny", "mistral-small", "mistral-medium", "mistral-large-latest"]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "mistral-tiny"
|
||
modelDisplayLabel: "Mistral"
|
||
# Drop Default params parameters from the request. See default params in guide linked below.
|
||
# NOTE: For Mistral, it is necessary to drop the following parameters or you will encounter a 422 Error:
|
||
dropParams: ["stop", "user", "frequency_penalty", "presence_penalty"]
|
||
```
|
||
|
||
|
||
|
||
|
||
## Ollama
|
||
> Ollama API key: Required but ignored - [Ollama OpenAI Compatibility](https://github.com/ollama/ollama/blob/main/docs/openai.md)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
- Download models with ollama run command. See [Ollama Library](https://ollama.com/library)
|
||
- It's recommend to use the value "current_model" for the `titleModel` to avoid loading more than 1 model per conversation.
|
||
- Doing so will dynamically use the current conversation model for the title generation.
|
||
- The example includes a top 5 popular model list from the Ollama Library, which was last updated on March 1, 2024, for your convenience.
|
||
|
||
```yaml
|
||
- name: "Ollama"
|
||
apiKey: "ollama"
|
||
# use 'host.docker.internal' instead of localhost if running LibreChat in a docker container
|
||
baseURL: "http://localhost:11434/v1/chat/completions"
|
||
models:
|
||
default: [
|
||
"llama2",
|
||
"mistral",
|
||
"codellama",
|
||
"dolphin-mixtral",
|
||
"mistral-openorca"
|
||
]
|
||
# fetching list of models is supported but the `name` field must start
|
||
# with `ollama` (case-insensitive), as it does in this example.
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "current_model"
|
||
summarize: false
|
||
summaryModel: "current_model"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "Ollama"
|
||
```
|
||
|
||
!!! tip "Ollama -> llama3"
|
||
|
||
Note: Once `stop` was removed from the [default parameters](./custom_config.md#default-parameters), the issue highlighted below should no longer exist.
|
||
|
||
However, in case you experience the behavior where `llama3` does not stop generating, add this `addParams` block to the config:
|
||
|
||
```yaml
|
||
- name: "Ollama"
|
||
apiKey: "ollama"
|
||
baseURL: "http://host.docker.internal:11434/v1/"
|
||
models:
|
||
default: [
|
||
"llama3"
|
||
]
|
||
fetch: false # fetching list of models is not supported
|
||
titleConvo: true
|
||
titleModel: "current_model"
|
||
summarize: false
|
||
summaryModel: "current_model"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "Ollama"
|
||
addParams:
|
||
"stop": [
|
||
"<|start_header_id|>",
|
||
"<|end_header_id|>",
|
||
"<|eot_id|>",
|
||
"<|reserved_special_token"
|
||
]
|
||
```
|
||
|
||
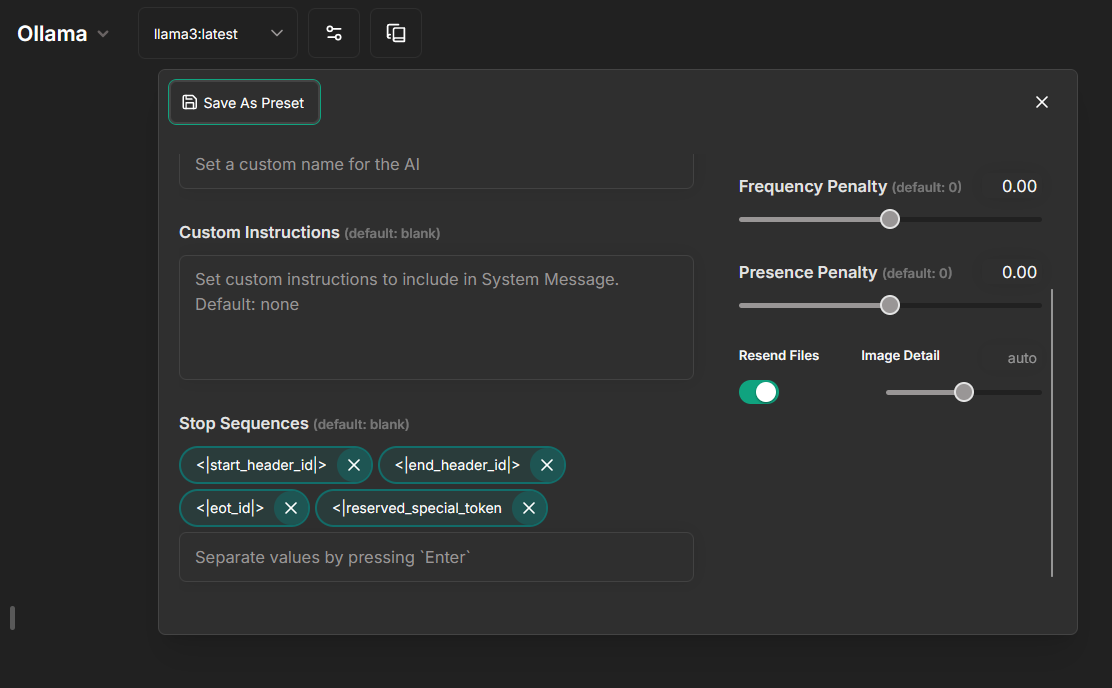
If you are only using `llama3` with **Ollama**, it's fine to set the `stop` parameter at the config level via `addParams`.
|
||
|
||
However, if you are using multiple models, it's now recommended to add stop sequences from the frontend via conversation parameters and presets.
|
||
|
||
For example, we can omit `addParams`:
|
||
|
||
```yaml
|
||
- name: "Ollama"
|
||
apiKey: "ollama"
|
||
baseURL: "http://host.docker.internal:11434/v1/"
|
||
models:
|
||
default: [
|
||
"llama3:latest",
|
||
"mistral"
|
||
]
|
||
fetch: false # fetching list of models is not supported
|
||
titleConvo: true
|
||
titleModel: "current_model"
|
||
modelDisplayLabel: "Ollama"
|
||
```
|
||
|
||
And use these settings (best to also save it):
|
||
|
||
|
||
|
||
## Openrouter
|
||
> OpenRouter API key: [openrouter.ai/keys](https://openrouter.ai/keys)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided, fetching list of models is recommended as API token rates and pricing used for token credit balances when models are fetched.
|
||
|
||
- `stop` is no longer included as a default parameter, so there is no longer a need to include it in [`dropParams`](./custom_config.md#dropparams), unless you would like to completely prevent users from configuring this field.
|
||
|
||
- **Known issue:** you should not use `OPENROUTER_API_KEY` as it will then override the `openAI` endpoint to use OpenRouter as well.
|
||
|
||
```yaml
|
||
- name: "OpenRouter"
|
||
# For `apiKey` and `baseURL`, you can use environment variables that you define.
|
||
# recommended environment variables:
|
||
apiKey: "${OPENROUTER_KEY}" # NOT OPENROUTER_API_KEY
|
||
baseURL: "https://openrouter.ai/api/v1"
|
||
models:
|
||
default: ["meta-llama/llama-3-70b-instruct"]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "meta-llama/llama-3-70b-instruct"
|
||
# Recommended: Drop the stop parameter from the request as Openrouter models use a variety of stop tokens.
|
||
dropParams: ["stop"]
|
||
modelDisplayLabel: "OpenRouter"
|
||
```
|
||
|
||
|
||
|
||
|
||
## Perplexity
|
||
> Perplexity API key: [perplexity.ai/settings/api](https://www.perplexity.ai/settings/api)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
- **Known issue:** fetching list of models is not supported.
|
||
- API may be strict for some models, and may not allow fields like `stop` and `frequency_penalty` may cause an error when set to 0, in which case, you should use [`dropParams`.](./custom_config.md#dropparams)
|
||
- The example includes a model list, which was last updated on February 27, 2024, for your convenience.
|
||
|
||
```yaml
|
||
- name: "Perplexity"
|
||
apiKey: "${PERPLEXITY_API_KEY}"
|
||
baseURL: "https://api.perplexity.ai/"
|
||
models:
|
||
default: [
|
||
"mistral-7b-instruct",
|
||
"sonar-small-chat",
|
||
"sonar-small-online",
|
||
"sonar-medium-chat",
|
||
"sonar-medium-online"
|
||
]
|
||
fetch: false # fetching list of models is not supported
|
||
titleConvo: true
|
||
titleModel: "sonar-medium-chat"
|
||
summarize: false
|
||
summaryModel: "sonar-medium-chat"
|
||
forcePrompt: false
|
||
dropParams: ["stop", "frequency_penalty"]
|
||
modelDisplayLabel: "Perplexity"
|
||
```
|
||
|
||
|
||
|
||
## ShuttleAI
|
||
> ShuttleAI API key: [shuttleai.app/keys](https://shuttleai.app/keys)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided, fetching list of models is recommended.
|
||
|
||
```yaml
|
||
- name: "ShuttleAI"
|
||
apiKey: "${SHUTTLEAI_API_KEY}"
|
||
baseURL: "https://api.shuttleai.app/v1"
|
||
models:
|
||
default: [
|
||
"shuttle-1", "shuttle-turbo"
|
||
]
|
||
fetch: true
|
||
titleConvo: true
|
||
titleModel: "gemini-pro"
|
||
summarize: false
|
||
summaryModel: "llama-summarize"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "ShuttleAI"
|
||
dropParams: ["user"]
|
||
```
|
||
|
||
|
||
|
||
## together.ai
|
||
> together.ai API key: [api.together.xyz/settings/api-keys](https://api.together.xyz/settings/api-keys)
|
||
|
||
**Notes:**
|
||
|
||
- **Known:** icon provided.
|
||
- **Known issue:** fetching list of models is not supported.
|
||
- The example includes a model list, which was last updated on February 27, 2024, for your convenience.
|
||
|
||
```yaml
|
||
- name: "together.ai"
|
||
apiKey: "${TOGETHERAI_API_KEY}"
|
||
baseURL: "https://api.together.xyz"
|
||
models:
|
||
default: [
|
||
"zero-one-ai/Yi-34B-Chat",
|
||
"Austism/chronos-hermes-13b",
|
||
"DiscoResearch/DiscoLM-mixtral-8x7b-v2",
|
||
"Gryphe/MythoMax-L2-13b",
|
||
"lmsys/vicuna-13b-v1.5",
|
||
"lmsys/vicuna-7b-v1.5",
|
||
"lmsys/vicuna-13b-v1.5-16k",
|
||
"codellama/CodeLlama-13b-Instruct-hf",
|
||
"codellama/CodeLlama-34b-Instruct-hf",
|
||
"codellama/CodeLlama-70b-Instruct-hf",
|
||
"codellama/CodeLlama-7b-Instruct-hf",
|
||
"togethercomputer/llama-2-13b-chat",
|
||
"togethercomputer/llama-2-70b-chat",
|
||
"togethercomputer/llama-2-7b-chat",
|
||
"NousResearch/Nous-Capybara-7B-V1p9",
|
||
"NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO",
|
||
"NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT",
|
||
"NousResearch/Nous-Hermes-Llama2-70b",
|
||
"NousResearch/Nous-Hermes-llama-2-7b",
|
||
"NousResearch/Nous-Hermes-Llama2-13b",
|
||
"NousResearch/Nous-Hermes-2-Yi-34B",
|
||
"openchat/openchat-3.5-1210",
|
||
"Open-Orca/Mistral-7B-OpenOrca",
|
||
"togethercomputer/Qwen-7B-Chat",
|
||
"snorkelai/Snorkel-Mistral-PairRM-DPO",
|
||
"togethercomputer/alpaca-7b",
|
||
"togethercomputer/falcon-40b-instruct",
|
||
"togethercomputer/falcon-7b-instruct",
|
||
"togethercomputer/GPT-NeoXT-Chat-Base-20B",
|
||
"togethercomputer/Llama-2-7B-32K-Instruct",
|
||
"togethercomputer/Pythia-Chat-Base-7B-v0.16",
|
||
"togethercomputer/RedPajama-INCITE-Chat-3B-v1",
|
||
"togethercomputer/RedPajama-INCITE-7B-Chat",
|
||
"togethercomputer/StripedHyena-Nous-7B",
|
||
"Undi95/ReMM-SLERP-L2-13B",
|
||
"Undi95/Toppy-M-7B",
|
||
"WizardLM/WizardLM-13B-V1.2",
|
||
"garage-bAInd/Platypus2-70B-instruct",
|
||
"mistralai/Mistral-7B-Instruct-v0.1",
|
||
"mistralai/Mistral-7B-Instruct-v0.2",
|
||
"mistralai/Mixtral-8x7B-Instruct-v0.1",
|
||
"teknium/OpenHermes-2-Mistral-7B",
|
||
"teknium/OpenHermes-2p5-Mistral-7B",
|
||
"upstage/SOLAR-10.7B-Instruct-v1.0"
|
||
]
|
||
fetch: false # fetching list of models is not supported
|
||
titleConvo: true
|
||
titleModel: "togethercomputer/llama-2-7b-chat"
|
||
summarize: false
|
||
summaryModel: "togethercomputer/llama-2-7b-chat"
|
||
forcePrompt: false
|
||
modelDisplayLabel: "together.ai"
|
||
```
|