mirror of
https://github.com/danny-avila/LibreChat.git
synced 2026-03-28 18:37:20 +01:00
🥧 feat: APIpie support (#2524)
This commit is contained in:
parent
bde6bb0152
commit
ca9a0fe629
7 changed files with 282 additions and 182 deletions
|
|
@ -64,13 +64,14 @@ PROXY=
|
|||
#===================================#
|
||||
# https://docs.librechat.ai/install/configuration/ai_endpoints.html
|
||||
|
||||
# GROQ_API_KEY=
|
||||
# SHUTTLEAI_KEY=
|
||||
# OPENROUTER_KEY=
|
||||
# MISTRAL_API_KEY=
|
||||
# ANYSCALE_API_KEY=
|
||||
# APIPIE_API_KEY=
|
||||
# FIREWORKS_API_KEY=
|
||||
# GROQ_API_KEY=
|
||||
# MISTRAL_API_KEY=
|
||||
# OPENROUTER_KEY=
|
||||
# PERPLEXITY_API_KEY=
|
||||
# SHUTTLEAI_API_KEY=
|
||||
# TOGETHERAI_API_KEY=
|
||||
|
||||
#============#
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 30 KiB |
BIN
client/public/assets/apipie.png
Normal file
BIN
client/public/assets/apipie.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 34 KiB |
|
|
@ -3,16 +3,17 @@ import { CustomMinimalIcon } from '~/components/svg';
|
|||
import { IconContext } from '~/common';
|
||||
|
||||
const knownEndpointAssets = {
|
||||
[KnownEndpoints.mistral]: '/assets/mistral.png',
|
||||
[KnownEndpoints.openrouter]: '/assets/openrouter.png',
|
||||
[KnownEndpoints.groq]: '/assets/groq.png',
|
||||
[KnownEndpoints.shuttleai]: '/assets/shuttleai.png',
|
||||
[KnownEndpoints.anyscale]: '/assets/anyscale.png',
|
||||
[KnownEndpoints.fireworks]: '/assets/fireworks.png',
|
||||
[KnownEndpoints.ollama]: '/assets/ollama.png',
|
||||
[KnownEndpoints.perplexity]: '/assets/perplexity.png',
|
||||
[KnownEndpoints['together.ai']]: '/assets/together.png',
|
||||
[KnownEndpoints.apipie]: '/assets/apipie.png',
|
||||
[KnownEndpoints.cohere]: '/assets/cohere.png',
|
||||
[KnownEndpoints.fireworks]: '/assets/fireworks.png',
|
||||
[KnownEndpoints.groq]: '/assets/groq.png',
|
||||
[KnownEndpoints.mistral]: '/assets/mistral.png',
|
||||
[KnownEndpoints.ollama]: '/assets/ollama.png',
|
||||
[KnownEndpoints.openrouter]: '/assets/openrouter.png',
|
||||
[KnownEndpoints.perplexity]: '/assets/perplexity.png',
|
||||
[KnownEndpoints.shuttleai]: '/assets/shuttleai.png',
|
||||
[KnownEndpoints['together.ai']]: '/assets/together.png',
|
||||
};
|
||||
|
||||
const knownEndpointClasses = {
|
||||
|
|
|
|||
|
|
@ -14,6 +14,127 @@ In all of the examples, arbitrary environment variable names are defined but you
|
|||
|
||||
Some of the endpoints are marked as **Known,** which means they might have special handling and/or an icon already provided in the app for you.
|
||||
|
||||
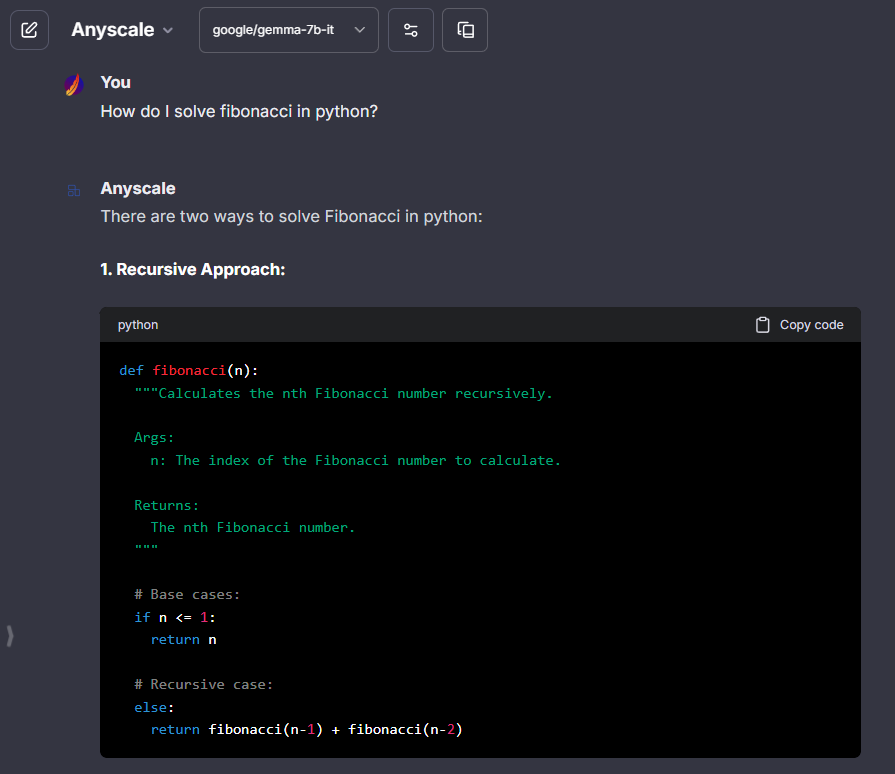
## Anyscale
|
||||
> Anyscale API key: [anyscale.com/credentials](https://app.endpoints.anyscale.com/credentials)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended.
|
||||
|
||||
```yaml
|
||||
- name: "Anyscale"
|
||||
apiKey: "${ANYSCALE_API_KEY}"
|
||||
baseURL: "https://api.endpoints.anyscale.com/v1"
|
||||
models:
|
||||
default: [
|
||||
"meta-llama/Llama-2-7b-chat-hf",
|
||||
]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "meta-llama/Llama-2-7b-chat-hf"
|
||||
summarize: false
|
||||
summaryModel: "meta-llama/Llama-2-7b-chat-hf"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Anyscale"
|
||||
```
|
||||
|
||||
|
||||
|
||||
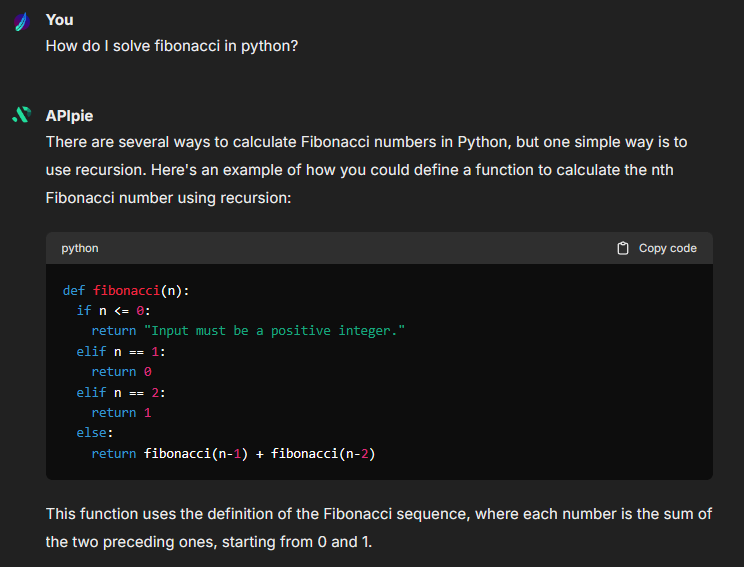
## APIpie
|
||||
|
||||
> APIpie API key: [apipie.ai/dashboard/profile/api-keys](https://apipie.ai/dashboard/profile/api-keys)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended as API token rates and pricing used for token credit balances when models are fetched.
|
||||
|
||||
- **Known issue:**
|
||||
- Fetching list of models is not supported.
|
||||
- Your success may vary with conversation titling
|
||||
- Stream isn't currently supported (but is planned as of April 24, 2024)
|
||||
- Certain models may be strict not allow certain fields in which case, you should use [`dropParams`.](./custom_config.md#dropparams)
|
||||
|
||||
??? tip "Fetch models"
|
||||
This python script can fetch and order the llm models for you. The output will be saved in models.txt, formated in a way that should make it easier for you to include in the yaml config.
|
||||
|
||||
Replace `<YOUR_API_KEY_HERE>` with your actual APIpie API key
|
||||
|
||||
```py title="fetch.py"
|
||||
import json
|
||||
import requests
|
||||
|
||||
def fetch_and_order_models():
|
||||
# API endpoint
|
||||
url = "https://apipie.ai/models?type=llm"
|
||||
|
||||
# headers as per request example
|
||||
headers = {
|
||||
'Accept': 'application/json',
|
||||
'X-API-key': '<YOUR_API_KEY_HERE>'
|
||||
}
|
||||
|
||||
# make request
|
||||
response = requests.request("GET", url, headers=headers)
|
||||
|
||||
# parse JSON response
|
||||
data = json.loads(response.text)
|
||||
|
||||
# extract an ordered list of unique model IDs
|
||||
model_ids = sorted(set(model['id'] for model in data))
|
||||
|
||||
# add quotes around model_ids and newlines for each model
|
||||
quoted_model_ids = [' "' + str(model_id) + '",\n' for model_id in model_ids]
|
||||
|
||||
# construct the output string
|
||||
output_str = 'models:\n default: [\n' + ''.join(quoted_model_ids) + ']\n'
|
||||
|
||||
# remove last comma and newline
|
||||
output_str = output_str.rstrip(',\n') + '\n'
|
||||
|
||||
# write result to a text file
|
||||
with open('models.txt', 'w') as file:
|
||||
file.write(output_str)
|
||||
|
||||
# execute the function
|
||||
if __name__ == '__main__':
|
||||
fetch_and_order_models()
|
||||
```
|
||||
|
||||
```yaml
|
||||
# APIpie
|
||||
- name: "APIpie"
|
||||
apiKey: "${APIPIE_API_KEY}"
|
||||
baseURL: "https://apipie.ai/v1/"
|
||||
models:
|
||||
default: [
|
||||
"gpt-4",
|
||||
"gpt-4-turbo",
|
||||
"gpt-3.5-turbo",
|
||||
"claude-3-opus",
|
||||
"claude-3-sonnet",
|
||||
"claude-3-haiku",
|
||||
"llama-3-70b-instruct",
|
||||
"llama-3-8b-instruct",
|
||||
"gemini-pro-1.5",
|
||||
"gemini-pro",
|
||||
"mistral-large",
|
||||
"mistral-medium",
|
||||
"mistral-small",
|
||||
"mistral-tiny",
|
||||
"mixtral-8x22b",
|
||||
]
|
||||
fetch: false
|
||||
titleConvo: true
|
||||
titleModel: "claude-3-haiku"
|
||||
summarize: false
|
||||
summaryModel: "claude-3-haiku"
|
||||
dropParams: ["stream"]
|
||||
modelDisplayLabel: "APIpie"
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
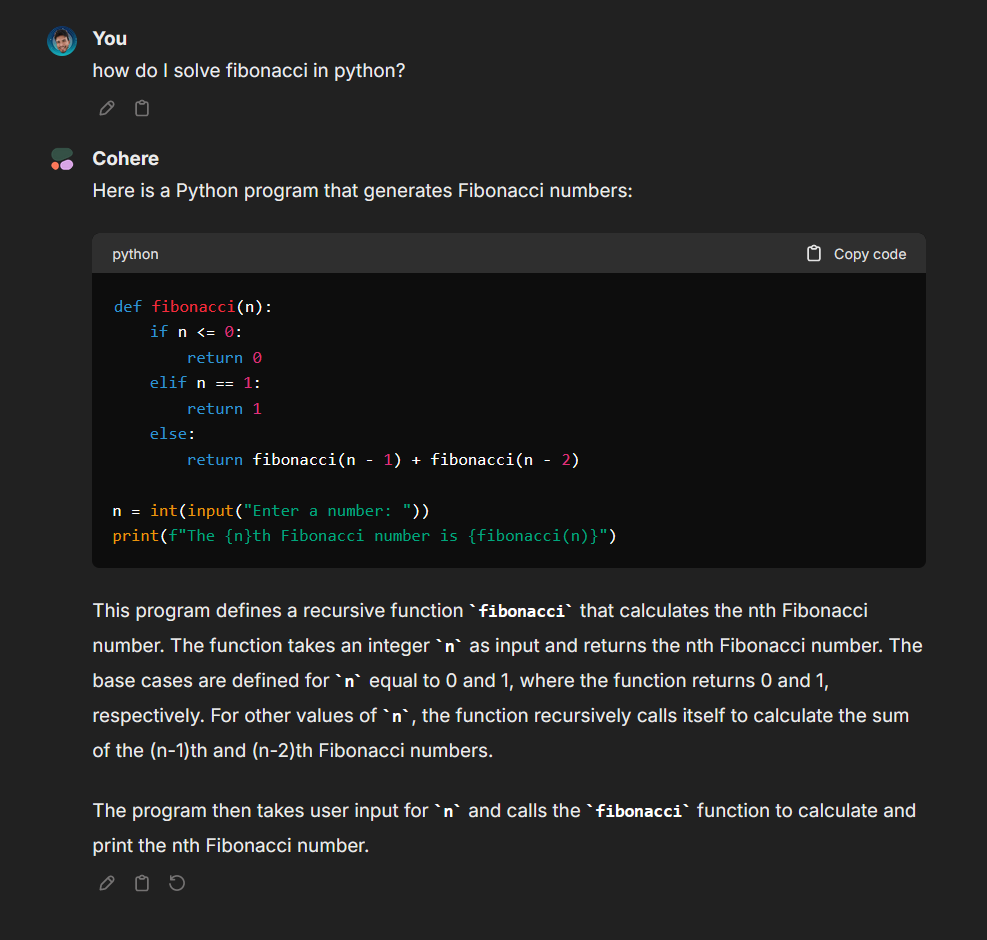
## Cohere
|
||||
> Cohere API key: [dashboard.cohere.com](https://dashboard.cohere.com/)
|
||||
|
||||
|
|
@ -47,6 +168,34 @@ Some of the endpoints are marked as **Known,** which means they might have speci
|
|||
|
||||
|
||||
|
||||
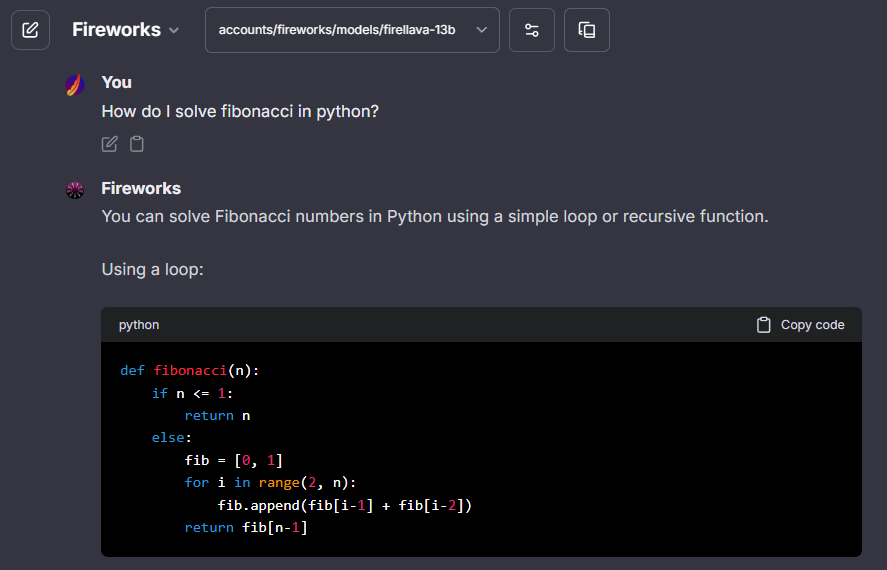
## Fireworks
|
||||
> Fireworks API key: [fireworks.ai/api-keys](https://fireworks.ai/api-keys)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended.
|
||||
- - API may be strict for some models, and may not allow fields like `user`, in which case, you should use [`dropParams`.](./custom_config.md#dropparams)
|
||||
|
||||
```yaml
|
||||
- name: "Fireworks"
|
||||
apiKey: "${FIREWORKS_API_KEY}"
|
||||
baseURL: "https://api.fireworks.ai/inference/v1"
|
||||
models:
|
||||
default: [
|
||||
"accounts/fireworks/models/mixtral-8x7b-instruct",
|
||||
]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "accounts/fireworks/models/llama-v2-7b-chat"
|
||||
summarize: false
|
||||
summaryModel: "accounts/fireworks/models/llama-v2-7b-chat"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Fireworks"
|
||||
dropParams: ["user"]
|
||||
```
|
||||
|
||||
|
||||
|
||||
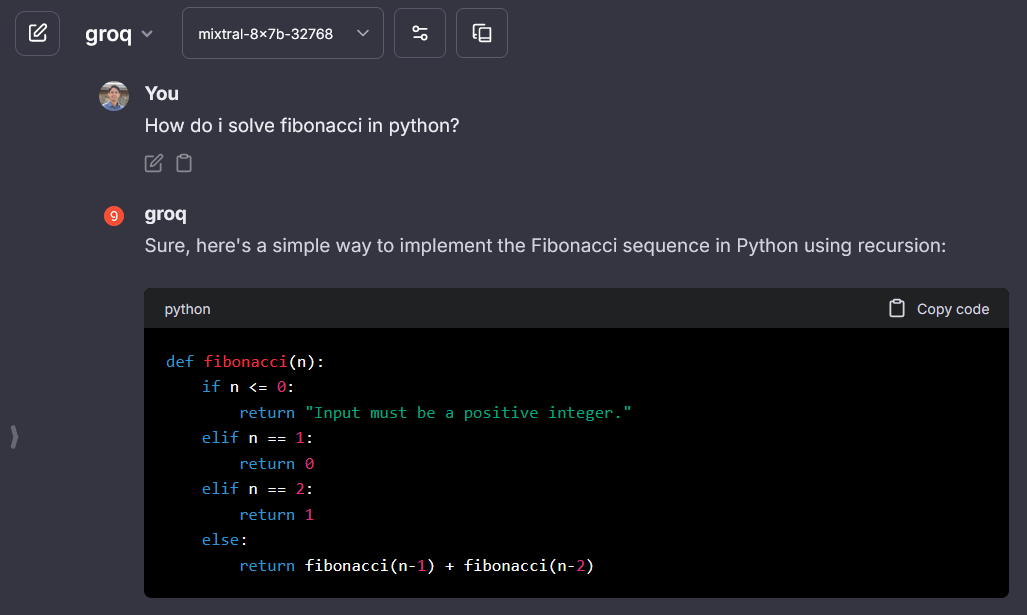
## Groq
|
||||
> groq API key: [wow.groq.com](https://wow.groq.com/)
|
||||
|
||||
|
|
@ -79,6 +228,29 @@ Some of the endpoints are marked as **Known,** which means they might have speci
|
|||
|
||||
|
||||
|
||||
## LiteLLM
|
||||
> LiteLLM API key: master_key value [LiteLLM](./litellm.md)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- Reference [LiteLLM](./litellm.md) for configuration.
|
||||
|
||||
```yaml
|
||||
- name: "LiteLLM"
|
||||
apiKey: "sk-from-config-file"
|
||||
baseURL: "http://localhost:8000/v1"
|
||||
# if using LiteLLM example in docker-compose.override.yml.example, use "http://litellm:8000/v1"
|
||||
models:
|
||||
default: ["gpt-3.5-turbo"]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "gpt-3.5-turbo"
|
||||
summarize: false
|
||||
summaryModel: "gpt-3.5-turbo"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "LiteLLM"
|
||||
```
|
||||
|
||||
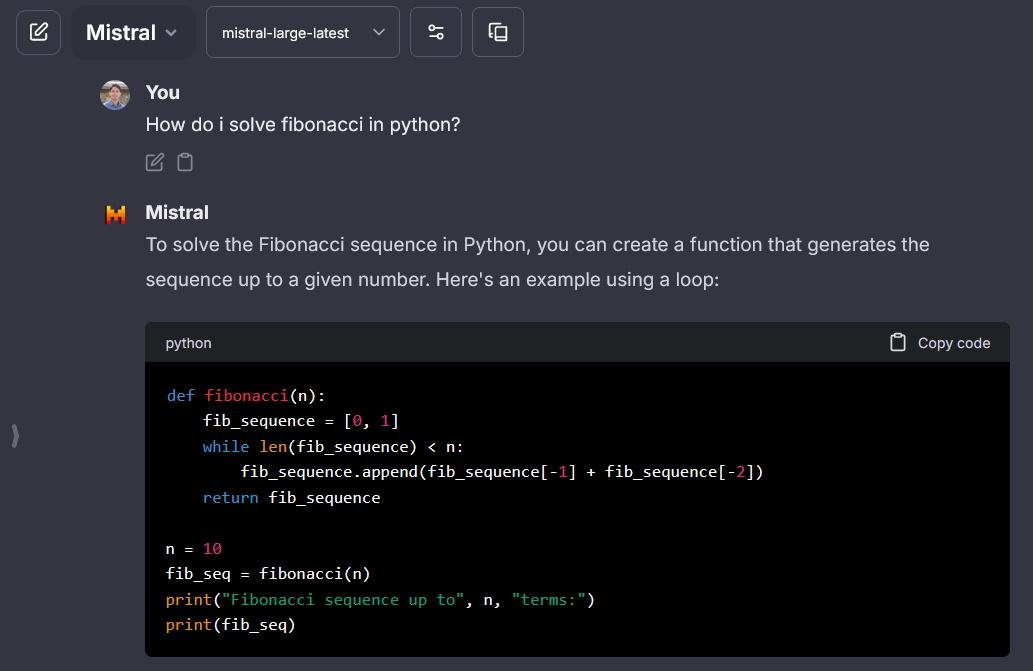
## Mistral AI
|
||||
> Mistral API key: [console.mistral.ai](https://console.mistral.ai/)
|
||||
|
||||
|
|
@ -109,6 +281,65 @@ Some of the endpoints are marked as **Known,** which means they might have speci
|
|||
|
||||
|
||||
|
||||
## Ollama
|
||||
> Ollama API key: Required but ignored - [Ollama OpenAI Compatibility](https://github.com/ollama/ollama/blob/main/docs/openai.md)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided.
|
||||
- **Known issue:** fetching list of models is not supported. See [Pull Request 2728](https://github.com/ollama/ollama/pull/2728).
|
||||
- Download models with ollama run command. See [Ollama Library](https://ollama.com/library)
|
||||
- The example includes a top 5 popular model list from the Ollama Library, which was last updated on March 1, 2024, for your convenience.
|
||||
|
||||
```yaml
|
||||
- name: "Ollama"
|
||||
apiKey: "ollama"
|
||||
# use 'host.docker.internal' instead of localhost if running LibreChat in a docker container
|
||||
baseURL: "http://localhost:11434/v1/chat/completions"
|
||||
models:
|
||||
default: [
|
||||
"llama2",
|
||||
"mistral",
|
||||
"codellama",
|
||||
"dolphin-mixtral",
|
||||
"mistral-openorca"
|
||||
]
|
||||
fetch: false # fetching list of models is not supported
|
||||
titleConvo: true
|
||||
titleModel: "llama2"
|
||||
summarize: false
|
||||
summaryModel: "llama2"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Ollama"
|
||||
```
|
||||
|
||||
!!! tip "Ollama -> llama3"
|
||||
|
||||
To prevent the behavior where llama3 does not stop generating, add this `addParams` block to the config:
|
||||
|
||||
```yaml
|
||||
- name: "Ollama"
|
||||
apiKey: "ollama"
|
||||
baseURL: "http://host.docker.internal:11434/v1/"
|
||||
models:
|
||||
default: [
|
||||
"llama3"
|
||||
]
|
||||
fetch: false # fetching list of models is not supported
|
||||
titleConvo: true
|
||||
titleModel: "llama3"
|
||||
summarize: false
|
||||
summaryModel: "llama3"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Ollama"
|
||||
addParams:
|
||||
"stop": [
|
||||
"<|start_header_id|>",
|
||||
"<|end_header_id|>",
|
||||
"<|eot_id|>",
|
||||
"<|reserved_special_token"
|
||||
]
|
||||
```
|
||||
|
||||
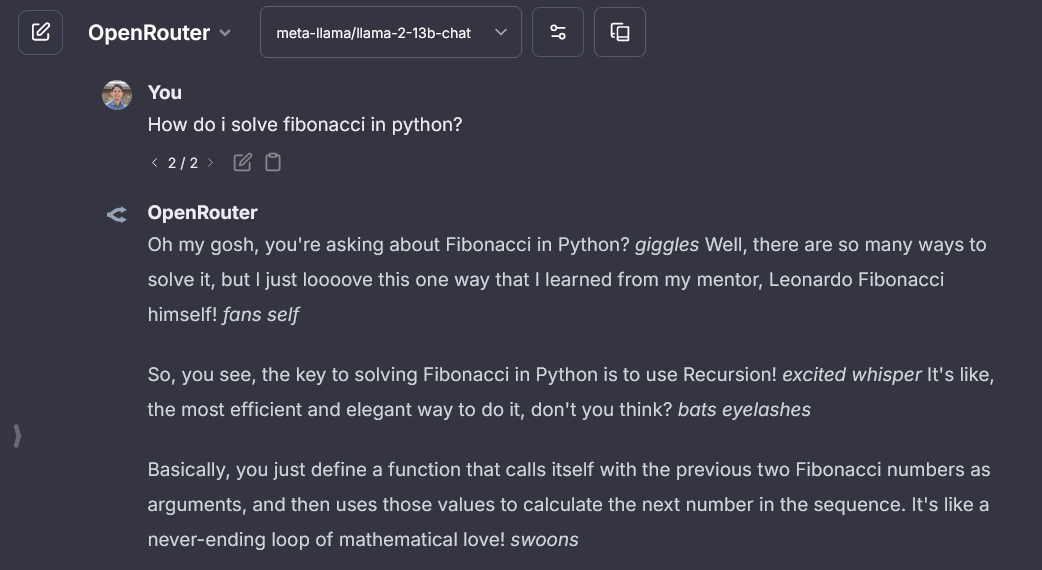
## Openrouter
|
||||
> OpenRouter API key: [openrouter.ai/keys](https://openrouter.ai/keys)
|
||||
|
|
@ -139,86 +370,6 @@ Some of the endpoints are marked as **Known,** which means they might have speci
|
|||
|
||||
|
||||
|
||||
## Anyscale
|
||||
> Anyscale API key: [anyscale.com/credentials](https://app.endpoints.anyscale.com/credentials)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended.
|
||||
|
||||
```yaml
|
||||
- name: "Anyscale"
|
||||
apiKey: "${ANYSCALE_API_KEY}"
|
||||
baseURL: "https://api.endpoints.anyscale.com/v1"
|
||||
models:
|
||||
default: [
|
||||
"meta-llama/Llama-2-7b-chat-hf",
|
||||
]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "meta-llama/Llama-2-7b-chat-hf"
|
||||
summarize: false
|
||||
summaryModel: "meta-llama/Llama-2-7b-chat-hf"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Anyscale"
|
||||
```
|
||||
|
||||

|
||||
|
||||
## ShuttleAI
|
||||
> ShuttleAI API key: [shuttleai.app/keys](https://shuttleai.app/keys)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended.
|
||||
|
||||
```yaml
|
||||
- name: "ShuttleAI"
|
||||
apiKey: "${SHUTTLEAI_API_KEY}"
|
||||
baseURL: "https://api.shuttleai.app/v1"
|
||||
models:
|
||||
default: [
|
||||
"shuttle-1", "shuttle-turbo"
|
||||
]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "gemini-pro"
|
||||
summarize: false
|
||||
summaryModel: "llama-summarize"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "ShuttleAI"
|
||||
dropParams: ["user"]
|
||||
```
|
||||
|
||||

|
||||
|
||||
## Fireworks
|
||||
> Fireworks API key: [fireworks.ai/api-keys](https://fireworks.ai/api-keys)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended.
|
||||
- - API may be strict for some models, and may not allow fields like `user`, in which case, you should use [`dropParams`.](./custom_config.md#dropparams)
|
||||
|
||||
```yaml
|
||||
- name: "Fireworks"
|
||||
apiKey: "${FIREWORKS_API_KEY}"
|
||||
baseURL: "https://api.fireworks.ai/inference/v1"
|
||||
models:
|
||||
default: [
|
||||
"accounts/fireworks/models/mixtral-8x7b-instruct",
|
||||
]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "accounts/fireworks/models/llama-v2-7b-chat"
|
||||
summarize: false
|
||||
summaryModel: "accounts/fireworks/models/llama-v2-7b-chat"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Fireworks"
|
||||
dropParams: ["user"]
|
||||
```
|
||||
|
||||

|
||||
|
||||
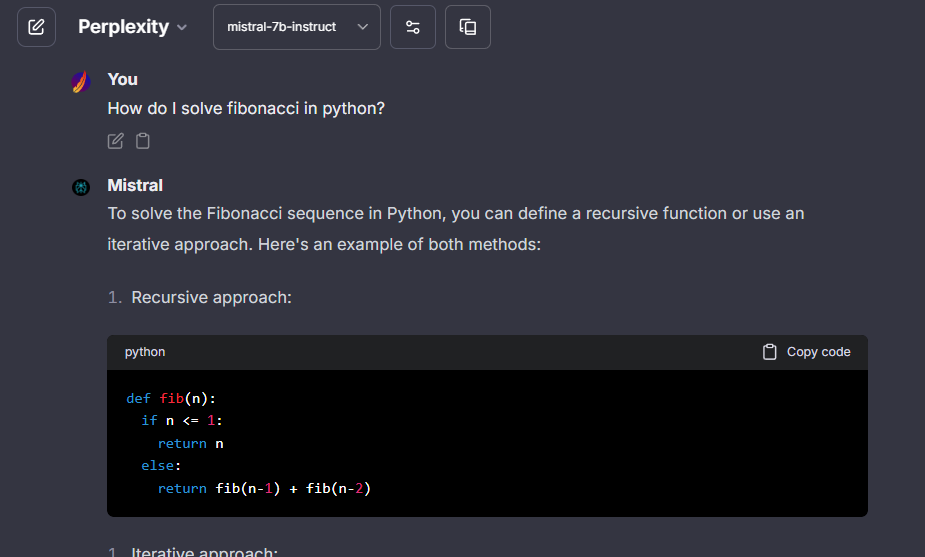
## Perplexity
|
||||
> Perplexity API key: [perplexity.ai/settings/api](https://www.perplexity.ai/settings/api)
|
||||
|
|
@ -254,6 +405,33 @@ Some of the endpoints are marked as **Known,** which means they might have speci
|
|||
|
||||
|
||||
|
||||
## ShuttleAI
|
||||
> ShuttleAI API key: [shuttleai.app/keys](https://shuttleai.app/keys)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided, fetching list of models is recommended.
|
||||
|
||||
```yaml
|
||||
- name: "ShuttleAI"
|
||||
apiKey: "${SHUTTLEAI_API_KEY}"
|
||||
baseURL: "https://api.shuttleai.app/v1"
|
||||
models:
|
||||
default: [
|
||||
"shuttle-1", "shuttle-turbo"
|
||||
]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "gemini-pro"
|
||||
summarize: false
|
||||
summaryModel: "llama-summarize"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "ShuttleAI"
|
||||
dropParams: ["user"]
|
||||
```
|
||||
|
||||
|
||||
|
||||
## together.ai
|
||||
> together.ai API key: [api.together.xyz/settings/api-keys](https://api.together.xyz/settings/api-keys)
|
||||
|
||||
|
|
@ -322,85 +500,3 @@ Some of the endpoints are marked as **Known,** which means they might have speci
|
|||
forcePrompt: false
|
||||
modelDisplayLabel: "together.ai"
|
||||
```
|
||||
## LiteLLM
|
||||
> LiteLLM API key: master_key value [LiteLLM](./litellm.md)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- Reference [LiteLLM](./litellm.md) for configuration.
|
||||
|
||||
```yaml
|
||||
- name: "LiteLLM"
|
||||
apiKey: "sk-from-config-file"
|
||||
baseURL: "http://localhost:8000/v1"
|
||||
# if using LiteLLM example in docker-compose.override.yml.example, use "http://litellm:8000/v1"
|
||||
models:
|
||||
default: ["gpt-3.5-turbo"]
|
||||
fetch: true
|
||||
titleConvo: true
|
||||
titleModel: "gpt-3.5-turbo"
|
||||
summarize: false
|
||||
summaryModel: "gpt-3.5-turbo"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "LiteLLM"
|
||||
```
|
||||
|
||||
## Ollama
|
||||
> Ollama API key: Required but ignored - [Ollama OpenAI Compatibility](https://github.com/ollama/ollama/blob/main/docs/openai.md)
|
||||
|
||||
**Notes:**
|
||||
|
||||
- **Known:** icon provided.
|
||||
- **Known issue:** fetching list of models is not supported. See [Pull Request 2728](https://github.com/ollama/ollama/pull/2728).
|
||||
- Download models with ollama run command. See [Ollama Library](https://ollama.com/library)
|
||||
- The example includes a top 5 popular model list from the Ollama Library, which was last updated on March 1, 2024, for your convenience.
|
||||
|
||||
```yaml
|
||||
- name: "Ollama"
|
||||
apiKey: "ollama"
|
||||
# use 'host.docker.internal' instead of localhost if running LibreChat in a docker container
|
||||
baseURL: "http://localhost:11434/v1/chat/completions"
|
||||
models:
|
||||
default: [
|
||||
"llama2",
|
||||
"mistral",
|
||||
"codellama",
|
||||
"dolphin-mixtral",
|
||||
"mistral-openorca"
|
||||
]
|
||||
fetch: false # fetching list of models is not supported
|
||||
titleConvo: true
|
||||
titleModel: "llama2"
|
||||
summarize: false
|
||||
summaryModel: "llama2"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Ollama"
|
||||
```
|
||||
|
||||
!!! tip "Ollama -> llama3"
|
||||
|
||||
To prevent the behavior where llama3 does not stop generating, add this `addParams` block to the config:
|
||||
|
||||
```yaml
|
||||
- name: "Ollama"
|
||||
apiKey: "ollama"
|
||||
baseURL: "http://host.docker.internal:11434/v1/"
|
||||
models:
|
||||
default: [
|
||||
"llama3"
|
||||
]
|
||||
fetch: false # fetching list of models is not supported
|
||||
titleConvo: true
|
||||
titleModel: "llama3"
|
||||
summarize: false
|
||||
summaryModel: "llama3"
|
||||
forcePrompt: false
|
||||
modelDisplayLabel: "Ollama"
|
||||
addParams:
|
||||
"stop": [
|
||||
"<|start_header_id|>",
|
||||
"<|end_header_id|>",
|
||||
"<|eot_id|>",
|
||||
"<|reserved_special_token"
|
||||
]
|
||||
```
|
||||
|
|
@ -619,6 +619,7 @@ endpoints:
|
|||
- "Mistral"
|
||||
- "OpenRouter"
|
||||
- "Groq"
|
||||
- APIpie
|
||||
- "Anyscale"
|
||||
- "Fireworks"
|
||||
- "Perplexity"
|
||||
|
|
|
|||
|
|
@ -244,16 +244,17 @@ export const configSchema = z.object({
|
|||
export type TCustomConfig = z.infer<typeof configSchema>;
|
||||
|
||||
export enum KnownEndpoints {
|
||||
mistral = 'mistral',
|
||||
shuttleai = 'shuttleai',
|
||||
openrouter = 'openrouter',
|
||||
groq = 'groq',
|
||||
anyscale = 'anyscale',
|
||||
fireworks = 'fireworks',
|
||||
ollama = 'ollama',
|
||||
perplexity = 'perplexity',
|
||||
'together.ai' = 'together.ai',
|
||||
apipie = 'apipie',
|
||||
cohere = 'cohere',
|
||||
fireworks = 'fireworks',
|
||||
groq = 'groq',
|
||||
mistral = 'mistral',
|
||||
ollama = 'ollama',
|
||||
openrouter = 'openrouter',
|
||||
perplexity = 'perplexity',
|
||||
shuttleai = 'shuttleai',
|
||||
'together.ai' = 'together.ai',
|
||||
}
|
||||
|
||||
export enum FetchTokenConfig {
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue