mirror of
https://github.com/danny-avila/LibreChat.git
synced 2025-12-16 08:20:14 +01:00
🐳 feat: RAG for Default Docker Compose Files + Docs Update (#2246)
* refactor(deploy-compose.yml): use long-syntax to avoid implicit folder creation of librechat.yaml * refactor(docker-compose.override.yml.example): use long-syntax to avoid implicit folder creation of librechat.yaml * chore: add simple health check for RAG_API_URL * chore: improve axios error handling, adding `logAxiosError` * chore: more informative message detailing RAG_API_URL path * feat: add rag_api and vectordb to default compose file * chore(rag.yml): update standalone rag compose file to use RAG_PORT * chore: documentation updates * docs: Update rag_api.md with images * Update rag_api.md * Update rag_api.md, assistants clarification * add RAG API note to breaking changes
This commit is contained in:
parent
6a6b2e79b0
commit
56ea0f9ae7
16 changed files with 306 additions and 74 deletions
12
README.md
12
README.md
|
|
@ -42,9 +42,11 @@
|
|||
|
||||
- 🖥️ UI matching ChatGPT, including Dark mode, Streaming, and latest updates
|
||||
- 💬 Multimodal Chat:
|
||||
- Upload and analyze images with GPT-4 and Gemini Vision 📸
|
||||
- General file support now available through the Assistants API integration. 🗃️
|
||||
- Local RAG in Active Development 🚧
|
||||
- Upload and analyze images with Claude 3, GPT-4, and Gemini Vision 📸
|
||||
- Chat with Files using Custom Endpoints, OpenAI, Azure, Anthropic, & Google. 🗃️
|
||||
- Advanced Agents with Files, Code Interpreter, Tools, and API Actions 🔦
|
||||
- Available through the [OpenAI Assistants API](https://platform.openai.com/docs/assistants/overview) 🌤️
|
||||
- Non-OpenAI Agents in Active Development 🚧
|
||||
- 🌎 Multilingual UI:
|
||||
- English, 中文, Deutsch, Español, Français, Italiano, Polski, Português Brasileiro,
|
||||
- Русский, 日本語, Svenska, 한국어, Tiếng Việt, 繁體中文, العربية, Türkçe, Nederlands, עברית
|
||||
|
|
@ -55,7 +57,9 @@
|
|||
- 🔍 Search all messages/conversations
|
||||
- 🔌 Plugins, including web access, image generation with DALL-E-3 and more
|
||||
- 👥 Multi-User, Secure Authentication with Moderation and Token spend tools
|
||||
- ⚙️ Configure Proxy, Reverse Proxy, Docker, many Deployment options, and completely Open-Source
|
||||
- ⚙️ Configure Proxy, Reverse Proxy, Docker, & many Deployment options
|
||||
- 📖 Completely Open-Source & Built in Public
|
||||
- 🧑🤝🧑 Community-driven development, support, and feedback
|
||||
|
||||
[For a thorough review of our features, see our docs here](https://docs.librechat.ai/features/plugins/introduction.html) 📚
|
||||
|
||||
|
|
|
|||
|
|
@ -156,6 +156,17 @@ const AppService = async (app) => {
|
|||
};
|
||||
}
|
||||
|
||||
try {
|
||||
const response = await fetch(`${process.env.RAG_API_URL}/health`);
|
||||
if (response?.ok && response?.status === 200) {
|
||||
logger.info(`RAG API is running and reachable at ${process.env.RAG_API_URL}.`);
|
||||
}
|
||||
} catch (error) {
|
||||
logger.warn(
|
||||
`RAG API is either not running or not reachable at ${process.env.RAG_API_URL}, you may experience errors with file uploads.`,
|
||||
);
|
||||
}
|
||||
|
||||
app.locals = {
|
||||
socialLogins,
|
||||
availableTools,
|
||||
|
|
|
|||
|
|
@ -1,11 +1,8 @@
|
|||
const axios = require('axios');
|
||||
const { HttpsProxyAgent } = require('https-proxy-agent');
|
||||
const { EModelEndpoint, defaultModels, CacheKeys } = require('librechat-data-provider');
|
||||
const { extractBaseURL, inputSchema, processModelData } = require('~/utils');
|
||||
const { extractBaseURL, inputSchema, processModelData, logAxiosError } = require('~/utils');
|
||||
const getLogStores = require('~/cache/getLogStores');
|
||||
const { logger } = require('~/config');
|
||||
|
||||
// const { getAzureCredentials, genAzureChatCompletion } = require('~/utils/');
|
||||
|
||||
const { openAIApiKey, userProvidedOpenAI } = require('./Config/EndpointService').config;
|
||||
|
||||
|
|
@ -77,29 +74,7 @@ const fetchModels = async ({
|
|||
models = input.data.map((item) => item.id);
|
||||
} catch (error) {
|
||||
const logMessage = `Failed to fetch models from ${azure ? 'Azure ' : ''}${name} API`;
|
||||
if (error.response) {
|
||||
logger.error(
|
||||
`${logMessage} The request was made and the server responded with a status code that falls out of the range of 2xx: ${
|
||||
error.message ? error.message : ''
|
||||
}`,
|
||||
{
|
||||
headers: error.response.headers,
|
||||
status: error.response.status,
|
||||
data: error.response.data,
|
||||
},
|
||||
);
|
||||
} else if (error.request) {
|
||||
logger.error(
|
||||
`${logMessage} The request was made but no response was received: ${
|
||||
error.message ? error.message : ''
|
||||
}`,
|
||||
{
|
||||
request: error.request,
|
||||
},
|
||||
);
|
||||
} else {
|
||||
logger.error(`${logMessage} Something happened in setting up the request`, error);
|
||||
}
|
||||
logAxiosError({ message: logMessage, error });
|
||||
}
|
||||
|
||||
return models;
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
const axios = require('axios');
|
||||
const { EModelEndpoint } = require('librechat-data-provider');
|
||||
const { logger } = require('~/config');
|
||||
const { logAxiosError } = require('~/utils');
|
||||
|
||||
/**
|
||||
* @typedef {Object} RetrieveOptions
|
||||
|
|
@ -54,33 +54,8 @@ async function retrieveRun({ thread_id, run_id, timeout, openai }) {
|
|||
const response = await axios.get(url, axiosConfig);
|
||||
return response.data;
|
||||
} catch (error) {
|
||||
const logMessage = '[retrieveRun] Failed to retrieve run data:';
|
||||
const timedOutMessage = 'Cannot read properties of undefined (reading \'status\')';
|
||||
if (error?.response && error?.response?.status) {
|
||||
logger.error(
|
||||
`${logMessage} The request was made and the server responded with a status code that falls out of the range of 2xx: ${
|
||||
error.message ? error.message : ''
|
||||
}`,
|
||||
{
|
||||
headers: error.response.headers,
|
||||
status: error.response.status,
|
||||
data: error.response.data,
|
||||
},
|
||||
);
|
||||
} else if (error.request) {
|
||||
logger.error(
|
||||
`${logMessage} The request was made but no response was received: ${
|
||||
error.message ? error.message : ''
|
||||
}`,
|
||||
{
|
||||
request: error.request,
|
||||
},
|
||||
);
|
||||
} else if (error?.message && !error?.message?.includes(timedOutMessage)) {
|
||||
logger.error(`${logMessage} Something happened in setting up the request`, {
|
||||
message: error.message,
|
||||
});
|
||||
}
|
||||
const message = '[retrieveRun] Failed to retrieve run data:';
|
||||
logAxiosError({ message, error });
|
||||
throw error;
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,13 +1,15 @@
|
|||
const loadYaml = require('./loadYaml');
|
||||
const tokenHelpers = require('./tokens');
|
||||
const azureUtils = require('./azureUtils');
|
||||
const logAxiosError = require('./logAxiosError');
|
||||
const extractBaseURL = require('./extractBaseURL');
|
||||
const findMessageContent = require('./findMessageContent');
|
||||
|
||||
module.exports = {
|
||||
...azureUtils,
|
||||
loadYaml,
|
||||
...tokenHelpers,
|
||||
...azureUtils,
|
||||
logAxiosError,
|
||||
extractBaseURL,
|
||||
findMessageContent,
|
||||
loadYaml,
|
||||
};
|
||||
|
|
|
|||
45
api/utils/logAxiosError.js
Normal file
45
api/utils/logAxiosError.js
Normal file
|
|
@ -0,0 +1,45 @@
|
|||
const { logger } = require('~/config');
|
||||
|
||||
/**
|
||||
* Logs Axios errors based on the error object and a custom message.
|
||||
*
|
||||
* @param {Object} options - The options object.
|
||||
* @param {string} options.message - The custom message to be logged.
|
||||
* @param {Error} options.error - The Axios error object.
|
||||
*/
|
||||
const logAxiosError = ({ message, error }) => {
|
||||
const timedOutMessage = 'Cannot read properties of undefined (reading \'status\')';
|
||||
if (error.response) {
|
||||
logger.error(
|
||||
`${message} The request was made and the server responded with a status code that falls out of the range of 2xx: ${
|
||||
error.message ? error.message : ''
|
||||
}. Error response data:\n`,
|
||||
{
|
||||
headers: error.response?.headers,
|
||||
status: error.response?.status,
|
||||
data: error.response?.data,
|
||||
},
|
||||
);
|
||||
} else if (error.request) {
|
||||
logger.error(
|
||||
`${message} The request was made but no response was received: ${
|
||||
error.message ? error.message : ''
|
||||
}. Error Request:\n`,
|
||||
{
|
||||
request: error.request,
|
||||
},
|
||||
);
|
||||
} else if (error?.message?.includes(timedOutMessage)) {
|
||||
logger.error(
|
||||
`${message}\nThe request either timed out or was unsuccessful. Error message:\n`,
|
||||
error,
|
||||
);
|
||||
} else {
|
||||
logger.error(
|
||||
`${message}\nSomething happened in setting up the request. Error message:\n`,
|
||||
error,
|
||||
);
|
||||
}
|
||||
};
|
||||
|
||||
module.exports = logAxiosError;
|
||||
|
|
@ -11,6 +11,7 @@ services:
|
|||
- 3080:3080
|
||||
depends_on:
|
||||
- mongodb
|
||||
- rag_api
|
||||
restart: always
|
||||
extra_hosts:
|
||||
- "host.docker.internal:host-gateway"
|
||||
|
|
@ -21,11 +22,14 @@ services:
|
|||
- NODE_ENV=production
|
||||
- MONGO_URI=mongodb://mongodb:27017/LibreChat
|
||||
- MEILI_HOST=http://meilisearch:7700
|
||||
- RAG_PORT=${RAG_PORT:-8000}
|
||||
- RAG_API_URL=http://rag_api:${RAG_PORT:-8000}
|
||||
volumes:
|
||||
- type: bind
|
||||
source: ./librechat.yaml
|
||||
target: /app/librechat.yaml
|
||||
- ./images:/app/client/public/images
|
||||
- ./librechat.yaml:/app/librechat.yaml
|
||||
- ./logs:/app/api/logs
|
||||
- ./uploads:/app/uploads
|
||||
client:
|
||||
build:
|
||||
context: .
|
||||
|
|
@ -61,3 +65,25 @@ services:
|
|||
- MEILI_NO_ANALYTICS=true
|
||||
volumes:
|
||||
- ./meili_data_v1.7:/meili_data
|
||||
vectordb:
|
||||
image: ankane/pgvector:latest
|
||||
environment:
|
||||
POSTGRES_DB: mydatabase
|
||||
POSTGRES_USER: myuser
|
||||
POSTGRES_PASSWORD: mypassword
|
||||
restart: always
|
||||
volumes:
|
||||
- pgdata2:/var/lib/postgresql/data
|
||||
rag_api:
|
||||
image: ghcr.io/danny-avila/librechat-rag-api-dev-lite:latest
|
||||
environment:
|
||||
- DB_HOST=vectordb
|
||||
- RAG_PORT=${RAG_PORT:-8000}
|
||||
restart: always
|
||||
depends_on:
|
||||
- vectordb
|
||||
env_file:
|
||||
- .env
|
||||
|
||||
volumes:
|
||||
pgdata2:
|
||||
|
|
|
|||
|
|
@ -16,7 +16,9 @@ version: '3.4'
|
|||
# services:
|
||||
# api:
|
||||
# volumes:
|
||||
# - ./librechat.yaml:/app/librechat.yaml
|
||||
# - type: bind
|
||||
# source: ./librechat.yaml
|
||||
# target: /app/librechat.yaml
|
||||
# image: ghcr.io/danny-avila/librechat:latest
|
||||
|
||||
# ---------------------------------------------------
|
||||
|
|
@ -26,7 +28,9 @@ version: '3.4'
|
|||
# # USE LIBRECHAT CONFIG FILE
|
||||
# api:
|
||||
# volumes:
|
||||
# - ./librechat.yaml:/app/librechat.yaml
|
||||
# - type: bind
|
||||
# source: ./librechat.yaml
|
||||
# target: /app/librechat.yaml
|
||||
|
||||
# # LOCAL BUILD
|
||||
# api:
|
||||
|
|
@ -93,6 +97,10 @@ version: '3.4'
|
|||
# ports:
|
||||
# - 7700:7700
|
||||
|
||||
# # USE RAG API IMAGE WITH LOCAL EMBEDDINGS SUPPORT
|
||||
# rag_api:
|
||||
# image: ghcr.io/danny-avila/librechat-rag-api-dev:latest
|
||||
|
||||
# # ADD OLLAMA
|
||||
# ollama:
|
||||
# image: ollama/ollama:latest
|
||||
|
|
|
|||
|
|
@ -10,6 +10,7 @@ services:
|
|||
- "${PORT}:${PORT}"
|
||||
depends_on:
|
||||
- mongodb
|
||||
- rag_api
|
||||
image: ghcr.io/danny-avila/librechat-dev:latest
|
||||
restart: always
|
||||
user: "${UID}:${GID}"
|
||||
|
|
@ -19,10 +20,13 @@ services:
|
|||
- HOST=0.0.0.0
|
||||
- MONGO_URI=mongodb://mongodb:27017/LibreChat
|
||||
- MEILI_HOST=http://meilisearch:7700
|
||||
- RAG_PORT=${RAG_PORT:-8000}
|
||||
- RAG_API_URL=http://rag_api:${RAG_PORT:-8000}
|
||||
volumes:
|
||||
- ./.env:/app/.env
|
||||
- type: bind
|
||||
source: ./.env
|
||||
target: /app/.env
|
||||
- ./images:/app/client/public/images
|
||||
- ./uploads:/app/uploads
|
||||
- ./logs:/app/api/logs
|
||||
mongodb:
|
||||
container_name: chat-mongodb
|
||||
|
|
@ -42,3 +46,25 @@ services:
|
|||
- MEILI_NO_ANALYTICS=true
|
||||
volumes:
|
||||
- ./meili_data_v1.7:/meili_data
|
||||
vectordb:
|
||||
image: ankane/pgvector:latest
|
||||
environment:
|
||||
POSTGRES_DB: mydatabase
|
||||
POSTGRES_USER: myuser
|
||||
POSTGRES_PASSWORD: mypassword
|
||||
restart: always
|
||||
volumes:
|
||||
- pgdata2:/var/lib/postgresql/data
|
||||
rag_api:
|
||||
image: ghcr.io/danny-avila/librechat-rag-api-dev-lite:latest
|
||||
environment:
|
||||
- DB_HOST=vectordb
|
||||
- RAG_PORT=${RAG_PORT:-8000}
|
||||
restart: always
|
||||
depends_on:
|
||||
- vectordb
|
||||
env_file:
|
||||
- .env
|
||||
|
||||
volumes:
|
||||
pgdata2:
|
||||
|
|
@ -9,6 +9,8 @@ weight: 2
|
|||
---
|
||||
|
||||
* 🤖[Custom Endpoints](../install/configuration/custom_config.md)
|
||||
* 🗃️ [RAG API (Chat with Files)](./rag_api.md)
|
||||
* 🔖 [Presets](./presets.md)
|
||||
* 🔌[Plugins](./plugins/index.md)
|
||||
* 🔌 [Introduction](./plugins/introduction.md)
|
||||
* 🛠️ [Make Your Own](./plugins/make_your_own.md)
|
||||
|
|
@ -17,7 +19,6 @@ weight: 2
|
|||
* 🖌️ [Stable Diffusion](./plugins/stable_diffusion.md)
|
||||
* 🧠 [Wolfram|Alpha](./plugins/wolfram.md)
|
||||
* ⚡ [Azure AI Search](./plugins/azure_ai_search.md)
|
||||
* 🔖 [Presets](./presets.md)
|
||||
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
---
|
||||
title: 🔨 Automated Moderation
|
||||
description: The Automated Moderation System uses a scoring mechanism to track user violations. As users commit actions like excessive logins, registrations, or messaging, they accumulate violation scores. Upon reaching a set threshold, the user and their IP are temporarily banned. This system ensures platform security by monitoring and penalizing rapid or suspicious activities.
|
||||
weight: -8
|
||||
weight: -7
|
||||
---
|
||||
## Automated Moderation System (optional)
|
||||
The Automated Moderation System uses a scoring mechanism to track user violations. As users commit actions like excessive logins, registrations, or messaging, they accumulate violation scores. Upon reaching a set threshold, the user and their IP are temporarily banned. This system ensures platform security by monitoring and penalizing rapid or suspicious activities.
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
---
|
||||
title: Plugins
|
||||
description: 🔌 All about plugins, how to make them, how use the official ChatGPT plugins, and how to configure custom plugins.
|
||||
weight: -10
|
||||
weight: -9
|
||||
---
|
||||
|
||||
# Plugins
|
||||
|
|
|
|||
148
docs/features/rag_api.md
Normal file
148
docs/features/rag_api.md
Normal file
|
|
@ -0,0 +1,148 @@
|
|||
---
|
||||
title: 🗃️ RAG API (Chat with Files)
|
||||
description: Retrieval-Augmented Generation (RAG) API for document indexing and retrieval using Langchain and FastAPI. This API integrates with LibreChat to provide context-aware responses based on user-uploaded files.
|
||||
weight: -10
|
||||
---
|
||||
|
||||
# RAG API
|
||||
|
||||
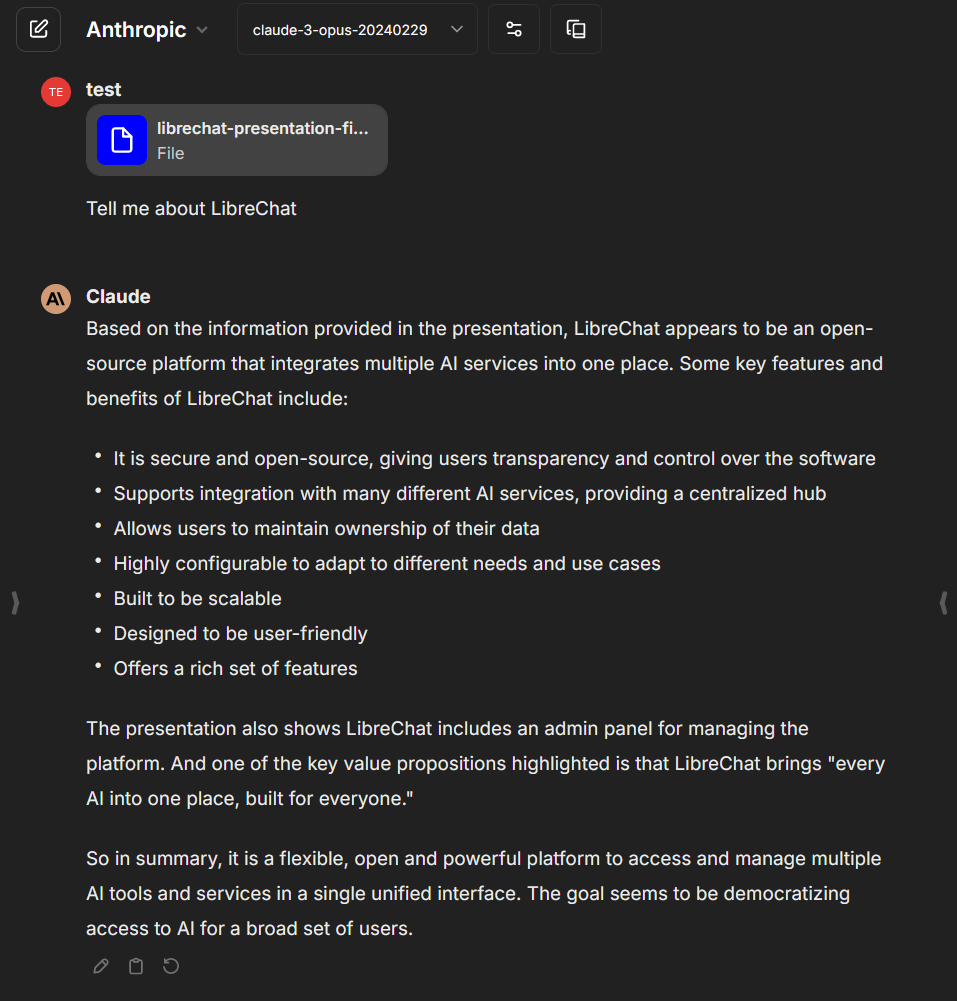
The **RAG (Retrieval-Augmented Generation) API** is a powerful tool that integrates with LibreChat to provide context-aware responses based on user-uploaded files.
|
||||
|
||||
It leverages LangChain, PostgresQL + PGVector, and Python FastAPI to index and retrieve relevant documents, enhancing the conversational experience.
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
**Currently, this feature is available to all Custom Endpoints, OpenAI, Azure OpenAi, Anthropic, and Google.**
|
||||
|
||||
OpenAI Assistants have their own implementation of RAG through the "Retrieval" capability. Learn more about it [here.](https://platform.openai.com/docs/assistants/tools/knowledge-retrieval)
|
||||
|
||||
It will still be useful to implement usage of the RAG API with the Assistants API since OpenAI charges for both file storage, and use of "Retrieval," and will be introduced in a future update.
|
||||
|
||||
Plugins support is not enabled as the whole "plugin/tool" framework will get a complete rework soon, making tools available to most endpoints (ETA Summer 2024).
|
||||
|
||||
**Still confused about RAG?** [Read the section I wrote below](#what-is-rag) explaining the general concept in more detail with a link to a helpful video.
|
||||
|
||||
## Features
|
||||
|
||||
- **Document Indexing**: The RAG API indexes user-uploaded files, creating embeddings for efficient retrieval.
|
||||
- **Semantic Search**: It performs semantic search over the indexed documents to find the most relevant information based on the user's input.
|
||||
- **Context-Aware Responses**: By augmenting the user's prompt with retrieved information, the API enables LibreChat to generate more accurate and contextually relevant responses.
|
||||
- **Asynchronous Processing**: The API supports asynchronous operations for improved performance and scalability.
|
||||
- **Flexible Configuration**: It allows customization of various parameters such as chunk size, overlap, and embedding models.
|
||||
|
||||
## Setup
|
||||
|
||||
To set up the RAG API with LibreChat, follow these steps:
|
||||
|
||||
### Docker Setup
|
||||
|
||||
For Docker, the setup is configured for you in both the default `docker-compose.yml` and `deploy-compose.yml` files, and you will just need to make sure you are using the latest docker image and compose files. Make sure to read the [Updating LibreChat guide for Docker](../install/installation/docker_compose_install.md#updating-librechat) if you are unsure how to update your Docker instance.
|
||||
|
||||
Docker uses the "lite" image of the RAG API by default, which only supports remote embeddings, leveraging embeddings proccesses from OpenAI or a remote service you have configured for HuggingFace/Ollama.
|
||||
|
||||
Local embeddings are supported by changing the image used by the default compose file, from `ghcr.io/danny-avila/librechat-rag-api-dev-lite:latest` to `ghcr.io/danny-avila/librechat-rag-api-dev:latest`.
|
||||
|
||||
As always, make these changes in your [Docker Compose Override File](../install/configuration/docker_override.md). You can find an example for exactly how to change the image in `docker-compose.override.yml.example` at the root of the project.
|
||||
|
||||
If you wish to see an example of a compose file that only includes the PostgresQL + PGVector database and the Python API, see `rag.yml` file at the root of the project.
|
||||
|
||||
**Important:** When using the default docker setup, the .env file, where configuration options can be set for the RAG API, is shared between LibreChat and the RAG API.
|
||||
|
||||
### Local Setup
|
||||
|
||||
Local, non-container setup is more hands-on, and for this you can refer to the [RAG API repo.](https://github.com/danny-avila/rag_api/)
|
||||
|
||||
In a local setup, you will need to manually set the `RAG_API_URL` in your LibreChat `.env` file to where it's available from your setup.
|
||||
|
||||
This contrasts Docker, where is already set in the default `docker-compose.yml` file.
|
||||
|
||||
## Configuration
|
||||
|
||||
The RAG API provides several configuration options that can be set using environment variables from an `.env` file accessible to the API. Most of them are optional, asides from the credentials/paths necessary for the provider you configured. In the default setup, only OPENAI_API_KEY is required.
|
||||
|
||||
**Important:** When using the default docker setup, the .env file is shared between LibreChat and the RAG API.
|
||||
|
||||
Here are some notable configurations:
|
||||
|
||||
- `OPENAI_API_KEY`: The API key for OpenAI API Embeddings (if using default settings).
|
||||
- `RAG_PORT`: The port number where the API server will run. Defaults to port 8000.
|
||||
- `RAG_HOST`: The hostname or IP address where the API server will run. Defaults to "0.0.0.0"
|
||||
- `COLLECTION_NAME`: The name of the collection in the vector store. Default is "testcollection".
|
||||
- `CHUNK_SIZE`: The size of the chunks for text processing. Default is "1500".
|
||||
- `CHUNK_OVERLAP`: The overlap between chunks during text processing. Default is "100".
|
||||
- `EMBEDDINGS_PROVIDER`: The embeddings provider to use. Options are "openai", "azure", "huggingface", "huggingfacetei", or "ollama". Default is "openai".
|
||||
- `EMBEDDINGS_MODEL`: The specific embeddings model to use from the configured provider. Default is dependent on the provider; for "openai", the model is "text-embedding-3-small".
|
||||
|
||||
There are several more configuration options.
|
||||
|
||||
For a complete list and their descriptions, please refer to the [RAG API repo.](https://github.com/danny-avila/rag_api/)
|
||||
|
||||
## Usage
|
||||
|
||||
Once the RAG API is set up and running, it seamlessly integrates with LibreChat. When a user uploads files to a conversation, the RAG API indexes those files and uses them to provide context-aware responses.
|
||||
|
||||
**To utilize the RAG API effectively:**
|
||||
|
||||
1. Ensure that the necessary files are uploaded to the conversation in LibreChat. If `RAG_API_URL` is not configured, or is not reachable, the file upload will fail.
|
||||
2. As the user interacts with the chatbot, the RAG API will automatically retrieve relevant information from the indexed files based on the user's input.
|
||||
3. The retrieved information will be used to augment the user's prompt, enabling LibreChat to generate more accurate and contextually relevant responses.
|
||||
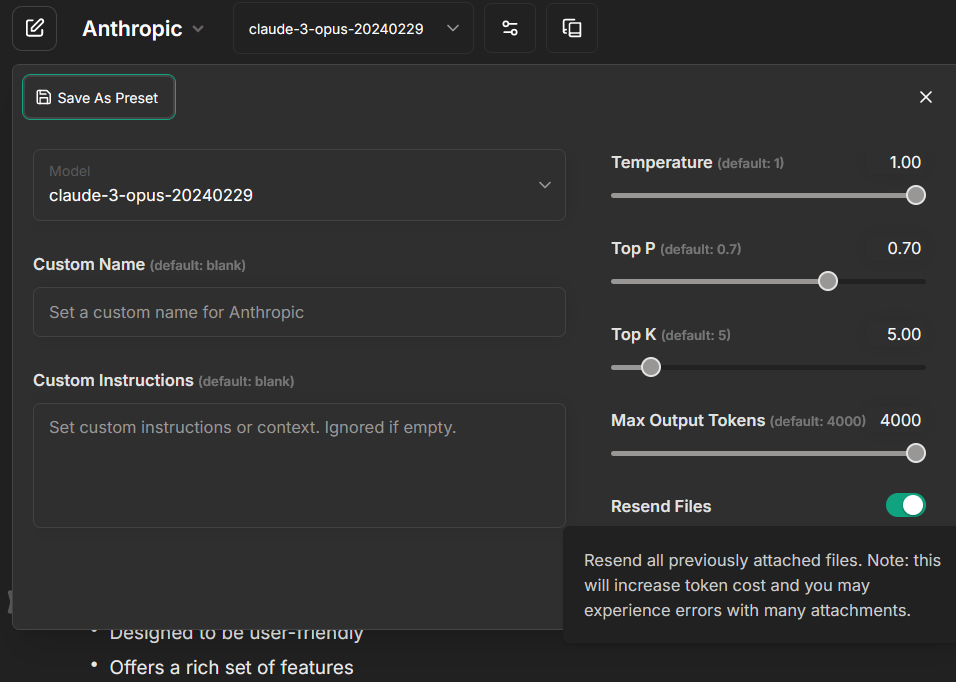
4. Craft your prompts carefully when you attach files as the default behavior is to query the vector store upon every new message to a conversation with a file attached.
|
||||
- You can disable the default behavior by toggling the "Resend Files" option to an "off" state, found in the conversation settings.
|
||||
- Doing so allows for targeted file queries, making it so that the "retrieval" will only be done when files are explicitly attached to a message.
|
||||
- 
|
||||
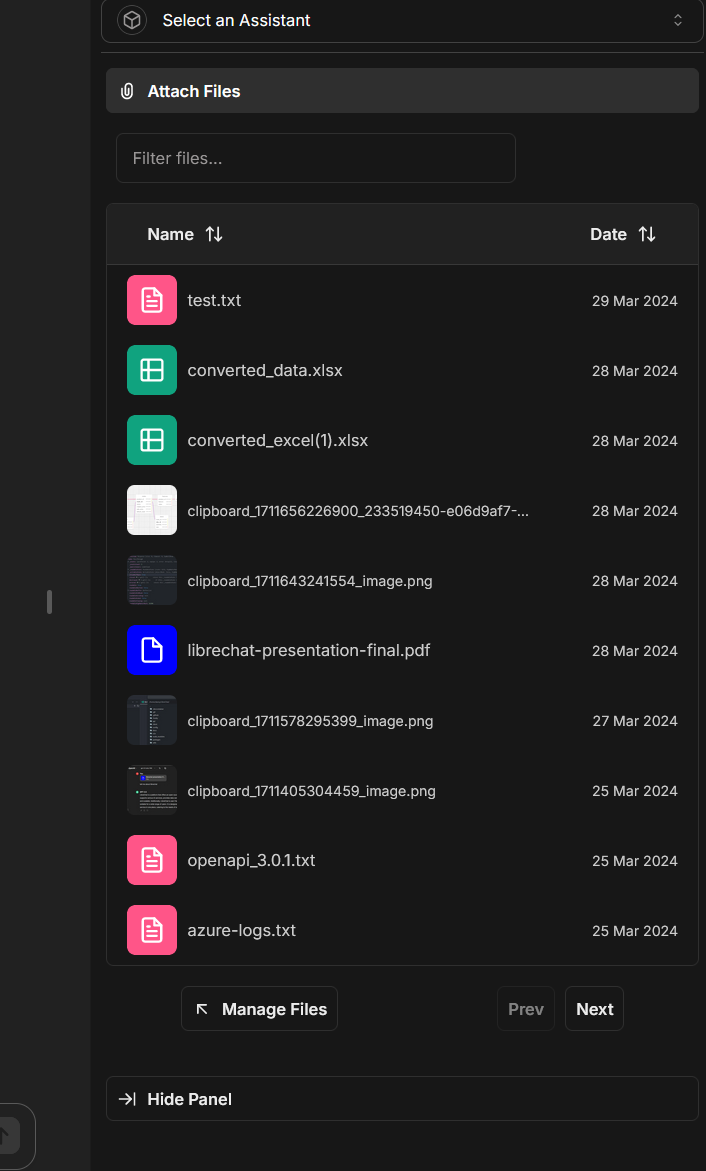
5. You only have to upload a file once to use it multiple times for RAG.
|
||||
- You can attach uploaded/indexed files to any new message or conversation using the Side Panel:
|
||||
- 
|
||||
- Note: The files must be in the "Host" storage, as "OpenAI" files are treated differently and exclusive to Assistants. In other words, they must not have been uploaded when the Assistants endpoint was selected and active. You can view and manage your files by clicking here from the Side Panel.
|
||||
- 
|
||||
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
If you encounter any issues while setting up or using the RAG API, consider the following:
|
||||
|
||||
- Double-check that all the required environment variables are correctly set in your `.env` file.
|
||||
- Ensure that the vector database is properly configured and accessible.
|
||||
- Verify that the OpenAI API key or other necessary credentials are valid.
|
||||
- Check both the LibreChat and RAG API logs for any error messages or warnings.
|
||||
|
||||
If the problem persists, please refer to the RAG API documentation or seek assistance from the LibreChat community on GitHub Discussions or Discord.
|
||||
|
||||
## What is RAG?
|
||||
|
||||
RAG, or Retrieval-Augmented Generation, is an AI framework designed to improve the quality and accuracy of responses generated by large language models (LLMs). It achieves this by grounding the LLM on external sources of knowledge, supplementing the model's internal representation of information.
|
||||
|
||||
### Key Benefits of RAG
|
||||
|
||||
1. **Access to up-to-date and reliable facts**: RAG ensures that the LLM has access to the most current and reliable information by retrieving relevant facts from an external knowledge base.
|
||||
2. **Transparency and trust**: Users can access the model's sources, allowing them to verify the accuracy of the generated responses and build trust in the system.
|
||||
3. **Reduced data leakage and hallucinations**: By grounding the LLM on a set of external, verifiable facts, RAG reduces the chances of the model leaking sensitive data or generating incorrect or misleading information.
|
||||
4. **Lower computational and financial costs**: RAG reduces the need for continuous training and updating of the model's parameters, potentially lowering the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
|
||||
|
||||
### How RAG Works
|
||||
|
||||
RAG consists of two main phases: retrieval and content generation.
|
||||
|
||||
1. **Retrieval Phase**: Algorithms search for and retrieve snippets of information relevant to the user's prompt or question from an external knowledge base. In an open-domain, consumer setting, these facts can come from indexed documents on the internet. In a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability.
|
||||
2. **Generative Phase**: The retrieved external knowledge is appended to the user's prompt and passed to the LLM. The LLM then draws from the augmented prompt and its internal representation of its training data to synthesize a tailored, engaging answer for the user. The answer can be passed to a chatbot with links to its sources.
|
||||
|
||||
### Challenges and Ongoing Research
|
||||
|
||||
While RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information and lowering the costs of constant retraining and updating, it is not perfect. Some challenges include:
|
||||
|
||||
1. **Recognizing unanswerable questions**: LLMs need to be explicitly trained to recognize questions they can't answer based on the available information. This may require fine-tuning on thousands of examples of answerable and unanswerable questions.
|
||||
2. **Improving retrieval and generation**: Ongoing research focuses on innovating at both ends of the RAG process: improving the retrieval of the most relevant information possible to feed the LLM, and optimizing the structure of that information to obtain the richest responses from the LLM.
|
||||
|
||||
In summary, RAG is a powerful framework that enhances the capabilities of LLMs by grounding them on external, verifiable knowledge. It helps to ensure more accurate, up-to-date, and trustworthy responses while reducing the costs associated with continuous model retraining. As research in this area progresses, we can expect further improvements in the quality and efficiency of LLM-powered conversational AI systems.
|
||||
|
||||
For a more detailed explanation of RAG, you can watch this informative video by IBM on Youtube:
|
||||
|
||||
[](https://www.youtube.com/watch?v=T-D1OfcDW1M)
|
||||
|
||||
## Conclusion
|
||||
|
||||
The RAG API is a powerful addition to LibreChat, enabling context-aware responses based on user-uploaded files. By leveraging Langchain and FastAPI, it provides efficient document indexing, retrieval, and generation capabilities. With its flexible configuration options and seamless integration, the RAG API enhances the conversational experience in LibreChat.
|
||||
|
||||
For more detailed information on the RAG API, including API endpoints, request/response formats, and advanced configuration, please refer to the official RAG API documentation.
|
||||
|
|
@ -12,6 +12,12 @@ weight: -10
|
|||
|
||||
---
|
||||
|
||||
## v0.7.0+
|
||||
|
||||
!!! info "🗃️ RAG API (Chat with Files)"
|
||||
|
||||
- **RAG API Update**: The default Docker compose files now include a Python API and Vector Database for RAG (Retrieval-Augmented Generation). Read more about this in the [RAG API page](../features/rag_api.md)
|
||||
|
||||
## v0.6.10+ (-dev build)
|
||||
|
||||
!!! info "🔎Meilisearch v1.7"
|
||||
|
|
|
|||
|
|
@ -37,8 +37,11 @@ weight: -10
|
|||
## 🪶 Features
|
||||
- 🖥️ UI matching ChatGPT, including Dark mode, Streaming, and 11-2023 updates
|
||||
- 💬 Multimodal Chat:
|
||||
- Upload and analyze images with GPT-4 and Gemini Vision 📸
|
||||
- More filetypes and Assistants API integration in Active Development 🚧
|
||||
- Upload and analyze images with Claude 3, GPT-4, and Gemini Vision 📸
|
||||
- Chat with Files using Custom Endpoints, OpenAI, Azure, Anthropic, & Google. 🗃️
|
||||
- Advanced Agents with Files, Code Interpreter, Tools, and API Actions 🔦
|
||||
- Available through the [OpenAI Assistants API](https://platform.openai.com/docs/assistants/overview) 🌤️
|
||||
- Non-OpenAI Agents in Active Development 🚧
|
||||
- 🌎 Multilingual UI:
|
||||
- English, 中文, Deutsch, Español, Français, Italiano, Polski, Português Brasileiro, Русский
|
||||
- 日本語, Svenska, 한국어, Tiếng Việt, 繁體中文, العربية, Türkçe, Nederlands
|
||||
|
|
@ -49,7 +52,9 @@ weight: -10
|
|||
- 🔍 Search all messages/conversations
|
||||
- 🔌 Plugins, including web access, image generation with DALL-E-3 and more
|
||||
- 👥 Multi-User, Secure Authentication with Moderation and Token spend tools
|
||||
- ⚙️ Configure Proxy, Reverse Proxy, Docker, many Deployment options, and completely Open-Source
|
||||
- ⚙️ Configure Proxy, Reverse Proxy, Docker, & many Deployment options
|
||||
- 📖 Completely Open-Source & Built in Public
|
||||
- 🧑🤝🧑 Community-driven development, support, and feedback
|
||||
|
||||
## 📃 All-In-One AI Conversations with LibreChat
|
||||
LibreChat brings together the future of assistant AIs with the revolutionary technology of OpenAI's ChatGPT. Celebrating the original styling, LibreChat gives you the ability to integrate multiple AI models. It also integrates and enhances original client features such as conversation and message search, prompt templates and plugins.
|
||||
|
|
|
|||
2
rag.yml
2
rag.yml
|
|
@ -21,7 +21,7 @@ services:
|
|||
- POSTGRES_USER=myuser
|
||||
- POSTGRES_PASSWORD=mypassword
|
||||
ports:
|
||||
- "8000:8000"
|
||||
- "${RAG_PORT}:${RAG_PORT}"
|
||||
depends_on:
|
||||
- vectordb
|
||||
env_file:
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue